

Learning Parameters
We have to understand that preparing a simple network is very easy task once you get the grasp of network structure. Now a days there are so many high level programming APIs that have already implemented this feature. One of the major platfom to work on machine learning is Tensorflow which also support Keras as higher level abstraction. But it is better to prepare a simple network by ourself at first. So, that this understanding will help us while working with higher level APIs.
Then what makes the process of getting required output from artificial neural network so difficult then? It is because of parameters that a network is comprised of. There are many parameters we have to consider while preparing a network. Some of the basic parmaeters are: learning rate, number of layers of neural network, number of neurons in a layer, optimizer function, which kind of network is more suitable for a specific purpose and features that must be passed as input to the network. We also must be familiar about data preparation process before passing them to neural network.Data preparation is a vague process so we will discuss about it in a separate post.
Now let’s discuss about each parameter in detail.
-
Learning Rate: This is the rate at which our network learns with provided data. We have be careful while choosing a leraning rate. If learning rate is too high the network will not converge. And if learning rate is too small network might take infinite time to converge i.e. find local mimina in case of gradient descent optimization.
-
Number of hidden layer in the network: Choosing number of hidden layers also plays an essential role while preparing a network. We have to be known with the fact taht more the number of hidden layers in the network more will be the complexity of network. We already know that the weight values transfer across the layers in network. So, if we chose very large number of hidden layer then the weight values might get attenuated over the layers and produce undesired results. While if the number of layers is too small then our network might not be able to learn required values. Having less number of hidden layer might lead to no learning of features at all. But having higher number of hidden layer might also cause overfitting due to over learning of weight values for given parameters.
-
Number of neurons: Neurons are basic building block of neural network. So, we have to consider carefully while choosing number of neurons in network. Having more neurons will lead to more complexity while having less will make network not able to learn. The effect of choosing more or leass number of neurons is same as that of choosing number of hidden layers.
-
Optimizer funtion: Optimizer function is the most essential part of artificial neural network. It is what makes the neural network so powerful. Without optimizer function the network will not be able to learn even with the presence of all above parameters. The main concept of optimizer function is adjusting weights in the network by minimizing value of loss function. Loss function calculates error in the network. Neural network work on the principle of minimizing this loss function and maximizing accuracy in the network. Accuracy is calculated by comparing expected output with predicted output. So, choosing an optimizer function is very essential step in ANN. But, there are so many variations that choosing a right one is also difficult. The most basic optimizer function is Gradient Descent Optimizer function and most popular is Adam Optimizer.
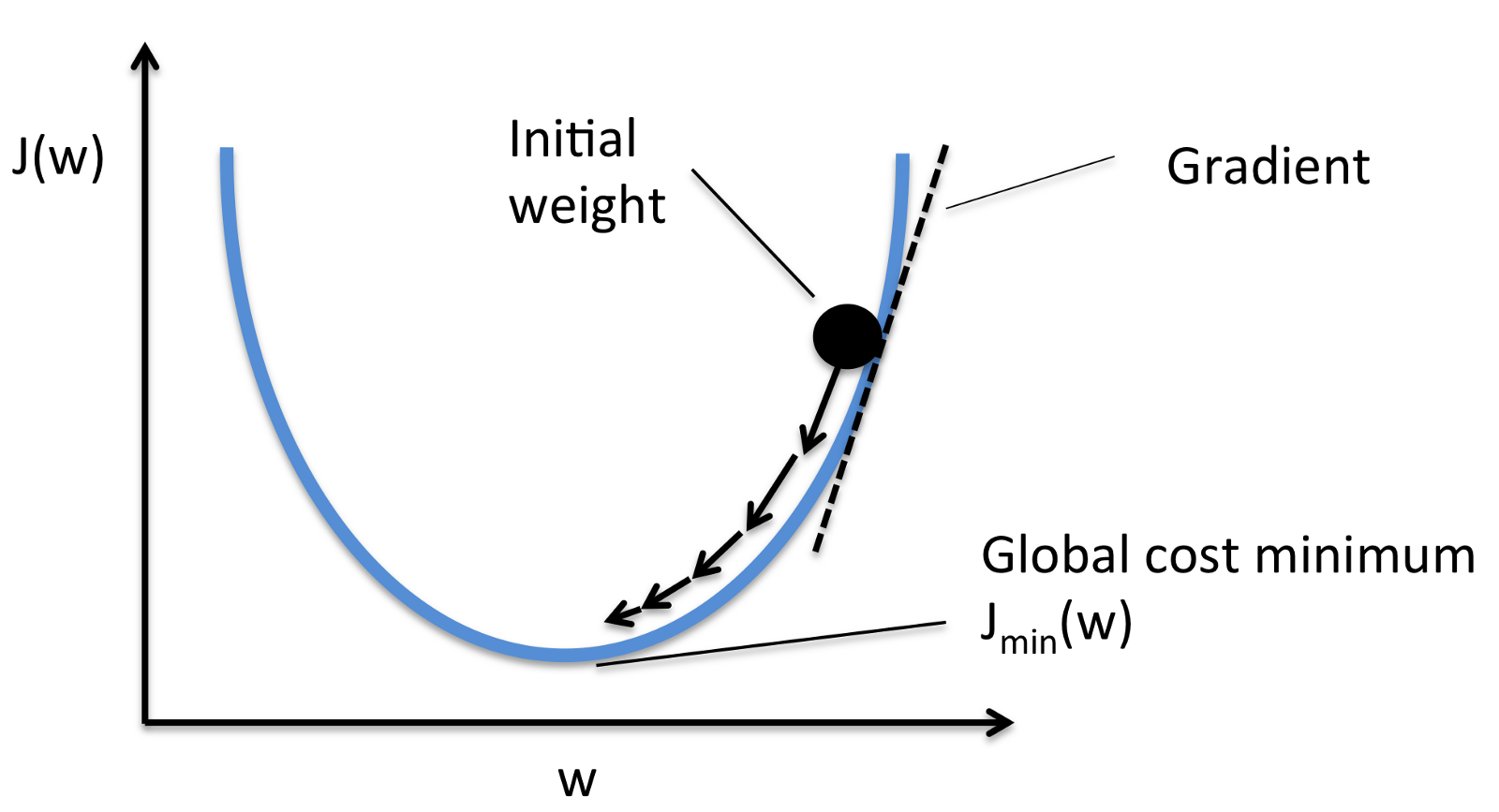
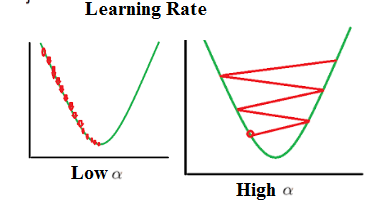
From figure we can see a simple illustration of gradient descent algorithm optimization method. We can know from the figure that purpose of optimizer function is to reduce loss as much as possible. So, it tries to find a minima called local minima.
It is better to find global minimum. But this comes as drawback of gradient descent optimizer since it is gets stuck in local miminum.
We also can see that if learning rate is too small it takes very small steps to reach local minimum so the time to learn will be very high. If learning rate is high it takes large steps so that it will be almost impossible to reach local minimum since the optimizer will go back and forth through the network.
- Type of network: There are so many variartions of network we can choose from like simple feed forward network, LSTM(Long Short Term Memory), CNN (Convolutional Neural Network). We have to choose them according to requirement.
There are many more parmaters like momemtum, dropout, type of cost function, type of accuracy function which have to be considered while preparing ANN to produce required result. But, these are the basic paramters to be considered.